The Cascade information reconciliation protocol.
Tutorial by Bruno Rijsman
See also:
Quantum key distribution (QKD) protocols.
All quantum key distribution (QKD) protocols involve using a combination of quantum communications (qubits) and classical communications (classical bits) to allow two parties Alice and Bob to agree on a secret key in such a way that our nefarious eavesdropper Eve cannot observe what the secret key is without being detected by Alice and Bob.
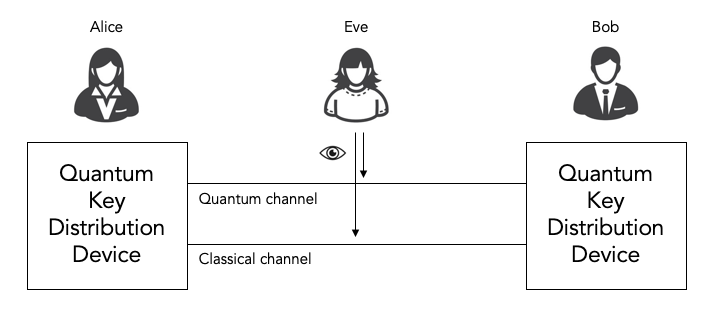
There are multiple quantum key distribution protocols, including for example BB84 and B92. All of these protocols consist of both a quantum phase and a classical post-processing phase.
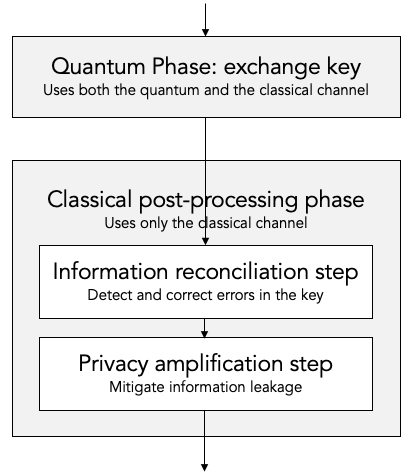
The quantum phase uses both the quantum channel and the classical channel to actually exchange the key.
The classical post-processing phase only uses the classical channel. The classical post-processing phase is further sub-divided into two parts:
Information reconciliation, which is responsible for detecting and correcting inevitable bit errors (noise) in the key that was exchanged during the quantum phase.
Privacy enhancement, which is responsible for mitigating the information leakage during the information reconciliation step.
In this document we only discuss one specific information reconciliation protocol, namely the Cascade protocol.
We won’t discuss privacy enhancement nor the quantum phase. Those interested in more details on the quantum phase can have a look at our simulaqron-bb84-python GitHub repository that contains our Python implementation of the quantum phase in the BB84 quantum key distribution protocol.
Key bit errors (noise).
Key distribution protocols always introduce some noise in the key. The key that Bob receives contains some noise (i.e. bit errors) as compared to the key that Alice sent. For that reason we refer to the key that Alice sent as the correct key and to the key that Bob received as the noisy key.
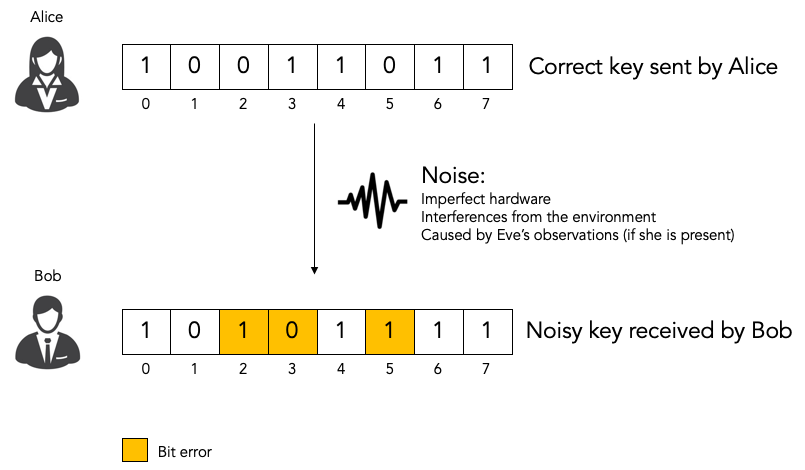
The noise can be introduced by imperfections in the hardware and by random fluctuations in the environment. Or the noise can be introduced by eavesdropper Eve observing traffic. Remember: in quantum mechanics observing a photon causes the photon to change and hence introduces detectable noise.
All quantum key distribution protocols provide an estimate of the noise level in the form of an estimated bit error rate. Bit error rate 0.0 means that no key bits have been flipped and bit error rate 1.0 means that all key bits have been flipped.
Classical post-processing.
If the estimated bit error rate is above some threshold we conclude that Eve is observing the traffic trying to determine the secret key. In that case, we abandon the key distribution attempt.
If the estimated bit error rate is below the threshold we perform classical post-processing, which consist of the two steps that we mentioned earlier. Both of these steps are classical protocols in the sense that they only involve classical communications and not any quantum communications.
Information reconciliation.
The first classical post-processing step is information reconciliation. Even if the bit error rate is below the threshold, it is not zero. There is still some noise: there are still bit errors in the noisy key that Bob received as compared to the correct key that Alice sent. The purpose of the information reconciliation step is to detect and correct these remaining bit errors.
There are multiple information reconciliation protocols. In this document we discuss only one specific protocol, namely the Cascade protocol.
The tricky part to information reconciliation is to avoid leaking (i.e. exposing) too much information about the key. Eve, the eavesdropper, can learn any information that we leak during the information reconciliation step. Even if she does not learn the entire key, learning any leaked partial information about the key simplifies her task of decrypting the encrypted traffic. Every bit of leaked key information halves the number of keys that Eve has to try during a brute force attack.
That said, it is unavoidable that the information reconciliation protocol leaks some limited amount of information. This is okay as long as the amount of leaked information is bounded and known, so that we can compensate for it.
Privacy amplification.
The second classical post-processing step is privacy amplification. The purpose of privacy amplification is to compensate for the information leakage in the information reconciliation step. Privacy amplification introduces extra randomness at the cost of reducing the effective key size.
In this document we do not discuss privacy amplification any further.
The Cascade protocol.
The Cascade protocol is one example of an information reconciliation protocol. The purpose of the Cascade protocol is to detect and to correct any remaining bit errors in the noisy key that Bob received relative to the correct key that Alice sent.
Let’s say that Alice and Bob are the two parties that have just run the quantum phase of a quantum key distribution such as BB84. Alice has the correct key and Bob has a noisy key, which is similar to Alice’s correct key but which has some limited number of bit errors (i.e. noise). Alice and Bob will now run the Cascade protocol to detect and correct any remaining bit errors in the Bob’s noisy key.
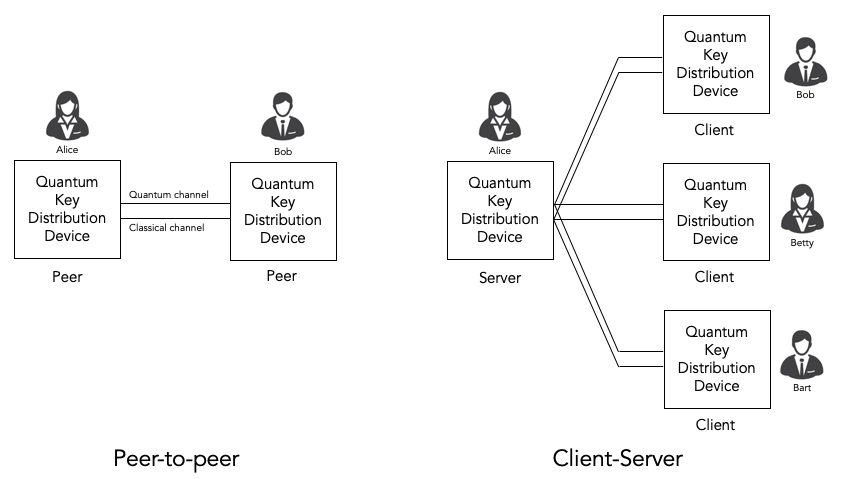
Cascade as a client-server protocol.
From a protocol point of view, it makes sense to describe the Cascade protocol in terms of a client-server protocol.
Bob takes the role of the client. As far as Cascade is concerned, he is the active party. He decides what needs to happen when. He does most of the computation. And he sends messages to Alice when he needs her to do something.
Alice takes the role of the server. As far as Cascade is concerned, her role is mostly passive. She waits for Bob to ask her simple questions and she provides the answers.
We will describe the Cascade protocol from the perspective of the client, i.e. from the perspective of Bob.
An interesting observation is that the Cascade protocol puts most of the complexity and most of the computational burden on the client. The server doesn’t do much except compute simple parities when asked to do so by the client. This is a very nice property for a client-server protocol. The server could have many (thousands) of sessions to clients, so it is very desirable that each session is simple and light-weight. The client will typically have only a few sessions to a few servers, so it is okay if the sessions are more complex and heavy-weight.
It is fair to say that quantum key distribution is currently often (almost always, perhaps) used to secure point-to-point links with a quantum key distribution device on either end of the link. From that perspective it is natural to think of Cascade as a peer-to-peer protocol.
That said, quantum key distribution in general and Cascade in particular could very well be deployed in true client-server scenarios. One example scenario is secure web traffic where a web server (e.g. Apache) has many session to many different web clients (e.g. Chrome web browsers) using the HTTPS protocol.
The classical channel.
Cascade is a fully classical protocol. It only involves the exchange of classical messages. It does not involve any quantum communications.
We assume that there is a classical channel between Alice and Bob that allows Alice and Bob to exchange classical messages as part of the Cascade protocol. We rely on classical techniques to provide reliability, flow-control, etc. (for example, we could use TCP/IP).
We do not require that the classical channel is encrypted: we assume that eavesdropper Eve can observe all classical messages in the clear.
Any requirement that the classical channel be encrypted would introduce a chicken-and-egg problem: we would need a quantum key distribution protocol to encrypt the classical channel, but the quantum key distribution protocol would need an encrypted classical channel.
We do, however, require that the classical channel provides authentication and integrity. We assume that there is a mechanism that allows Alice and Bob to verify that all classical messages were actually sent by Bob and Alice and have not been forged or tampered with by Eve.
This is needed to avoid woman-in-the-middle attacks by Eve, where Eve intercepts all classical traffic and pretends to be Bob to Alice and pretends to Alice to Bob.
We do not discuss how the authentication and integrity are implemented nor does the code in this repository contain any authentication or integrity mechanisms.
This is consistent with most of the literature on quantum key distribution. Most literature barely mentions the need for an authentication and integrity on the classical channel. Details on how to do it are even less forthcoming. This might give you the impression that it is a trivial matter not worth discussing. Nothing could be further from the truth!
Yes, it is true that authentication and integrity are considered to be well-solved problems for classical protocols. For authentication, classical protocols typically use either public key infrastructure (PKI) or pre-shared keys. For integrity, classical protocols typically use hash-based message authentication codes (HMAC) in combination with Diffie-Hellman or pre-shared keys to agree on the message authentication key.
But none of those options (pre-shared keys, public key infrastructure, Diffie-Hellman) are attractive options for quantum key distribution.
Public-key infrastructure and Diffie-Hellman are problematic because they are not quantum-safe: they rely on the assumption that factorization or modular logarithms are computationally difficult.
Pre-shared keys are somewhat acceptable for point-to-point connections, but they are really problematic in client-server scenarios where the server does not know a-priori which clients will connect to it. But more importantly, using pre-shared keys defeats the whole purpose of running a quantum key distribution protocol.
In summary: while the topic of authenticating the classical channel is usually glossed over, it is not at all obvious how to achieve it in the context of quantum key distribution.
Input and output of the Cascade protocol.
Let’s start by looking at the Cascade protocol as a black box algorithm, and let’s consider what the input and the output of the Cascade protocol are.
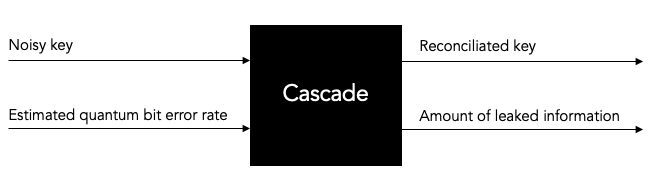
Input: noisy key and estimated quantum bit error rate (QBER).
Bob initiates the Cascade protocol after the quantum phase of the quantum key distribution has been completed.
At this point, Bob has the following information available to him, which is the input to the Cascade protocol.
Bob has the noisy key that he has received from Alice. Although a quantum key distribution protocol was used to agree on this key, there is nothing quantum about the key at this point. It is just a string of classical bits of a certain length (the key size).
As we described earlier, the quantum key distribution protocol introduces some noise when it delivers this key to Bob. Thus, Bob has a noisy key which has some bit errors compared to Alice’s correct key.
Bob does not know exactly how many bit errors there are or which bits are in error, but the quantum key distribution protocol does provide an estimate of the bit error rate, which also known as the quantum bit error rate (QBER).
Thus, we have two inputs to the Cascade protocol: the noisy key and the estimated quantum bit error rate (QBER).
Output: reconciliated key and amount of leaked information.
It is the job of the Cascade protocol to determine which bits exactly are in error and to fix them.
It is important to understand that Cascade does not guarantee that all bit errors are corrected. In other words, Bob’s reconciliated key is still not guaranteed to be the same as Alice’s correct key. Even after the reconciliation is complete, there is still a remaining bit error rate. The remaining bit error rate is orders of magnitude smaller than the original bit error rate before Cascade was run. But it is not zero. That is why we prefer to use the term reconciliated key and not corrected key, although the latter is also often used.
Cascade per-se does not contain any mechanism to detect and report whether the reconciliation was successful. It will neither detect nor report that there are any remaining bit errors after reconciliation. Some mechanism outside of Cascade is needed to validate whether the reconciliated key is correct or not.
The Cascade protocol can also keep track of exactly how much information was leaked. Specifically, Cascade running at Bob can keep track of which parities he asked Alice to compute. We must assume that Eve will also know about those parities. We can express the amount of leaked information in terms of leaked key bits (this is a logical abstraction - it does not indicate which specific key bits were leaked, it only provides a measure of how much information was leaked).
The amount of leaked information may be used by the privacy amplification phase that runs after the information reconciliation phase to determine how much amplification is needed.
Thus, the output of Cascade are the reconciliated key and the amount of leaked information.
Cascade Iterations.
Now we are ready to start describing the guts of the Cascade protocol, i.e. to describe in detail how it actually works.
Let’s define a single run of the Cascade protocol as Alice and Bob reconciliating (i.e. attempting to correct) a single key.
A single Cascade run consists of multiple iterations (these are also known as passes). Different variations of the Cascade protocol use different numbers of iterations. But we start by describing the original version of the Cascade protocol which uses four iterations.
Each Cascade iteration corrects some of the bit errors in the key. It is very probable (but not entirely certain) that all bit errors will have been corrected by the end of the last iteration.
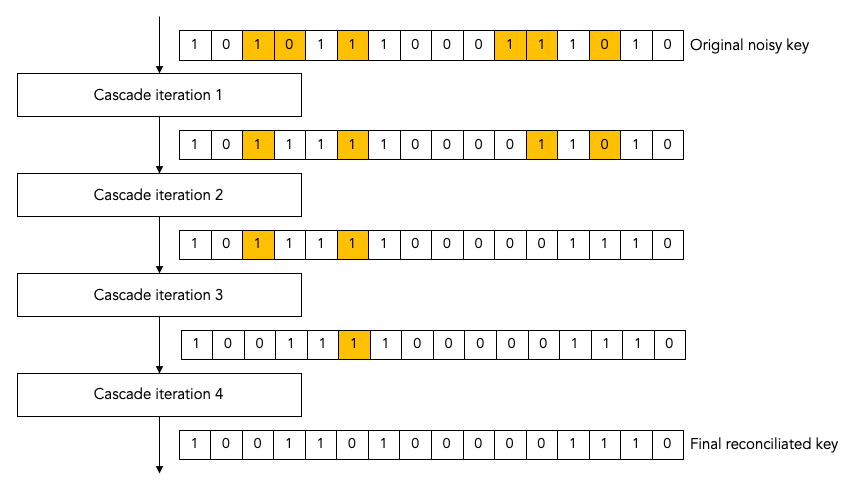
Note: for the sake of clarity, all of our diagrams show very small keys. In the above diagram, for example, we use 16-bit keys. In later diagrams we will use even smaller keys to make them fit in the diagram. In real life the keys can be much much larger: tens of thousands or even hundreds of thousands of bits.
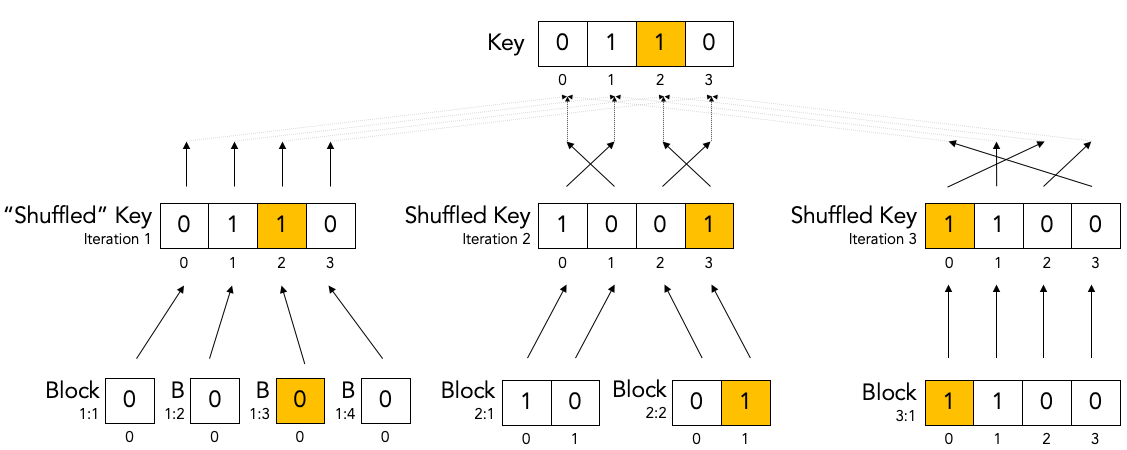
Key shuffling.
At the beginning of each iteration, except the first one, Bob randomly shuffles the bits in the noisy key. Shuffling means randomly reordering the bits in the key.
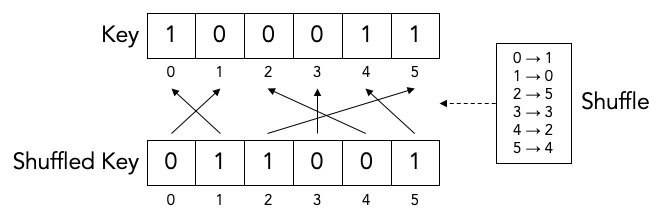
Later we will find out what the purpose of shuffling the key is. For now, we just point out that the shuffling is not intended to obfuscate the key for Eve. It is perfectly okay if the shuffling is only pseudo-random or even deterministic.
It is even okay if Eve knows what the shuffling permutation is (shown as the “Shuffle” in the above diagram) as long as the actual key values before (“Key”) or after the shuffling (“Shuffled key”) are not divulged. In fact, Bob needs to inform Alice what the shuffle permutation for each Cascade iteration is. It is no problem if the information about the shuffle permutation is sent in the clear and Eve can observe it.
As we mentioned, Bob re-shuffles his noisy key at the beginning of each iteration except the first one:
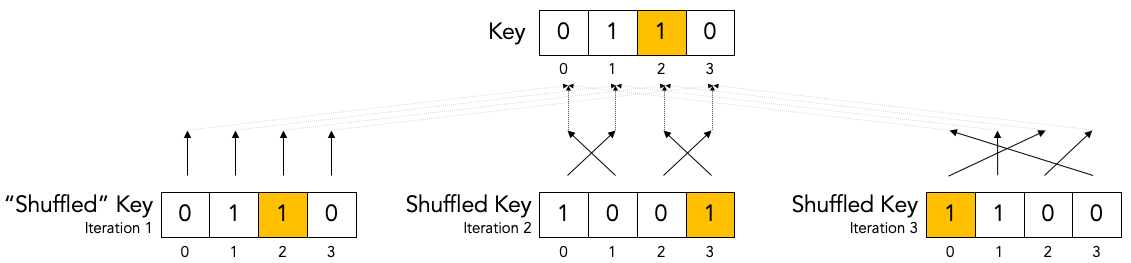
We put the word “shuffled” in quotes for the first iteration because they key is not really shuffled for the first iteration.
The important thing to observe is that any given bit in the original unshuffled key (for example bit number 2 which is marked in yellow) ends up in a different position in the shuffled key during each iteration.
Creation of the top-level blocks.
During each iteration, right after shuffling the key, Bob divides the shuffled key into equally sized blocks (the last block may be a smaller size if the key is not an exact multiple of the block size).
We will call these blocks top-level blocks to distinguish them from other types of blocks (the so-called sub-blocks) that will appear later in the protocol as a result of block splitting.
The size of the top-level blocks depends on two things:
The iteration number i. Early iterations have smaller block sizes (and hence more blocks) than later iterations.
The estimated quantum bit error rate Q. The higher the quantum bitter error rate, the smaller the block size.
Note: to make things fit on a page the block sizes are extremely small in this diagram. In real life, top-level blocks are much larger. Specifically, we would never see a single-bit top-level block.
There are many variations of the Cascade protocol, and one of the main differences between these variations is the exact formula for the block size ki as a function of the iteration number i and the quantum bit error rate Q.
For the original version of the Cascade protocol the formula is as follows:
k1= 0.73 / Q
k2= 2 * k1
k3= 2 * k2
k4= 2 * k3
Without getting into the mathematical details behind this formula, we can build up some intuition about the reasons behind it.
Later on, we will see that Cascade is able to correct a single bit error in a block but is not able to correct a double bit error in a block.
If we pick a block size 1/Q for the first iteration, then each block will is expected to contain a single bit error on average. That is just the definition of bit error rate. If the bit error rate is 1 error per 100 bits, then a block of 100 bits will contain on average one error.
Now, if we use 0.73/Q instead of 1/Q then we will have slightly smaller blocks than that. As a result we will have more blocks with zero errors (which are harmless) and fewer blocks with two errors (which are bad because they cannot be corrected).
On the other hand, we don’t want to make the blocks too small, because the smaller we make the blocks, the more information is leaked to Eve. Knowing the parity over more smaller blocks allows Eve know more about the key.
So, that explains the formula 0.73/Q for the first iteration. What about the doubling of the block size in each iteration?
Well, during each iteration Cascade corrects some number of errors. Thus the remaining quantum bit error rate for the next iteration is lower (i.e. fewer error bits). This allows us to use a bigger block size for the next iteration, and still have a low probability of two (uncorrectable) errors in a single block.
Detecting and correcting bit errors in each block.
After having shuffled the key and after having split the key into blocks for a given iteration, Bob sets out on the task of determining, for each block, whether or not there are any bit errors in that block and, if so, to correct those bit errors.
The process of doing so is a bit complex because Bob needs to do it in such a way that he leaks a minimum of information to eavesdropper Eve who is watching his every move.
Computing the error parity for each top-level block: even or odd.
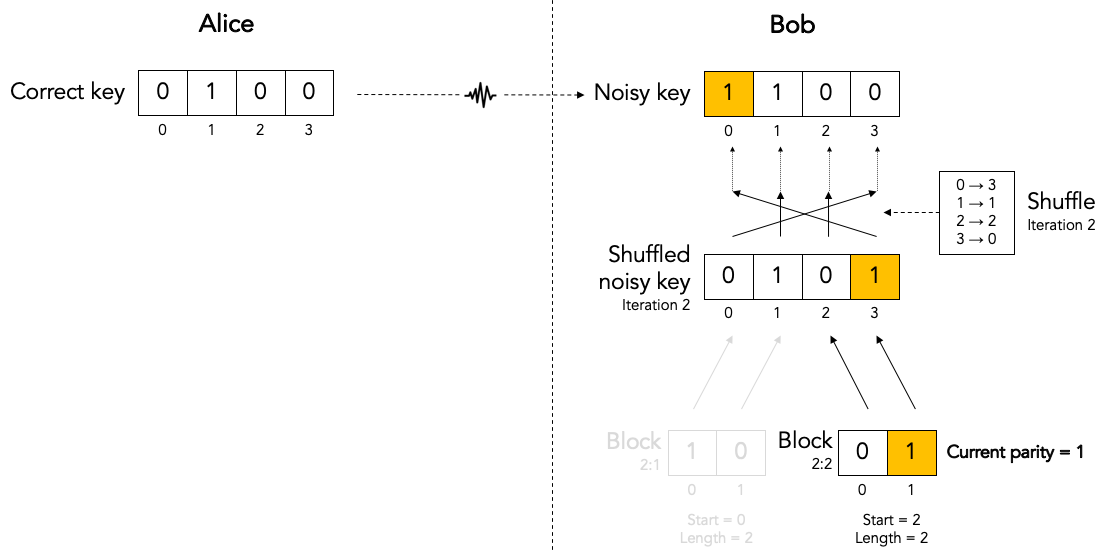
Computing the current parity.
Bob locally computes the current parity of each top-level block. This is a parity over some subset of bits in the shuffled noisy key that Bob has received from Alice. In the following example, Bob computes the parity of the 2nd top-level block in the 2nd iteration. That block has value 01 so its current parity is 1.
Computing the correct parity.
Next, Bob wants to know Alice’s perspective on the block parity. He already knows the “current parity” of the block in his own noisy key, but now he wants to know the “correct parity” of the same block in the Alice’s correct key.
There is no way for Bob to compute the correct parity himself. Bob does not have access to the correct key, only Alice does. Actually, that statement is a little bit too strong. It turns out that there is an exception to this statement. Hold on until we discuss block parity inference (BPI) near the end of this tutorial.
The solution is simple: Bob simply sends an ask parity message to Alice. The purpose of this message is to ask Alice to compute the correct parity.
Let’s first look at a very naive way of implementing the ask parity message, which is very inefficient but which makes the concept very clear:
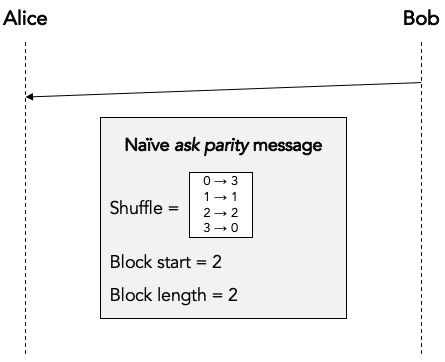
In this implementation Bob literally provides all the information that Alice needs to reconstruct the block and compute the correct parity:
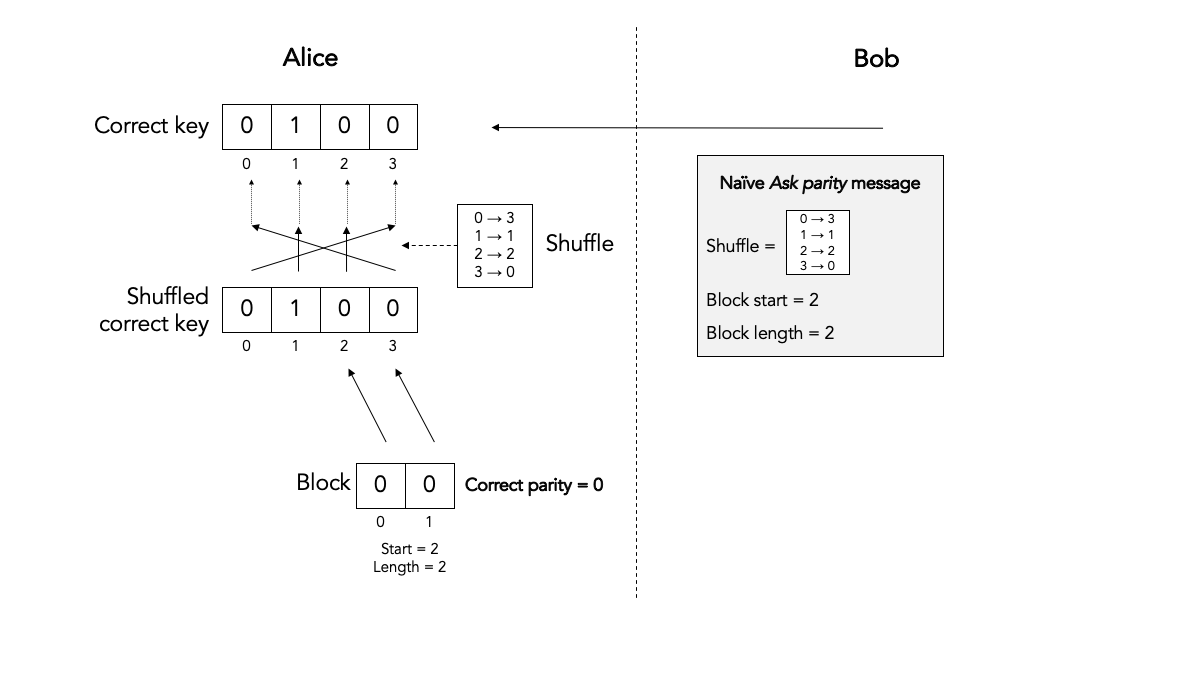
This is an inefficient way of computing the correct the parity. For one, the ask parity message can get very large because the shuffle permutation can get very large: here it is N numbers, where N is the key size (but it is easy to see that we could reduce N to the block size). Secondly, it requires Alice to spend processing time on reconstructing the shuffled key and the block.
An obvious optimization is for Bob to just cut to the chase and list the actual unshuffled key indexes over which Alice must compute the parity:
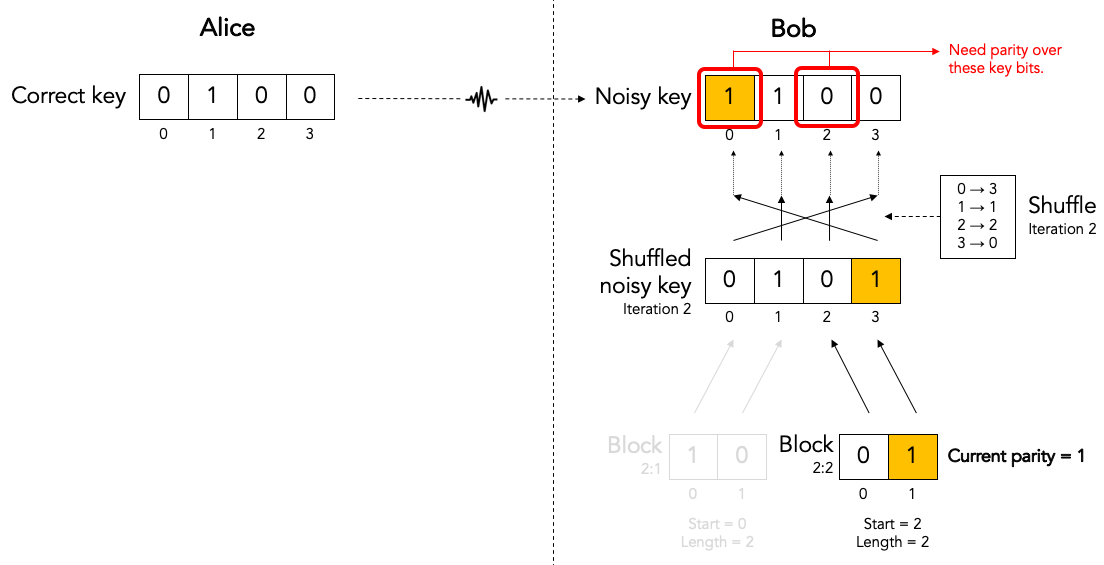
This allows Alice to just compute the correct parity without wasting CPU cycles on reconstructing the shuffled key and block:
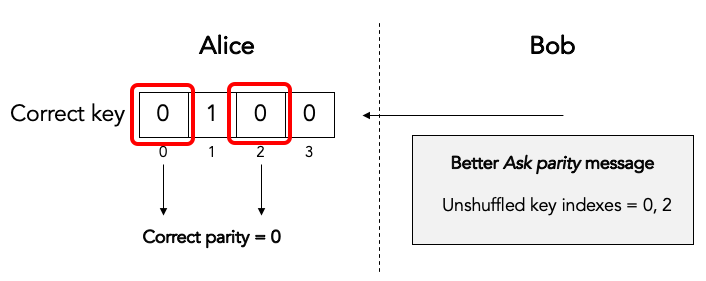
In both cases the ask parity message does not leak any information about the key (yet): it does not contain the value of any key bit or any other information about the key bits themselves.
It turns out that there are even more efficient ways of implementing the ask parity message. These rely on the fact that the key is only shuffled once per iteration and we ask for block parities many times per iteration. These optimizations are described in the implementation guide.
The only thing left to do is for Alice to send the correct parity back to Bob in a reply parity message:
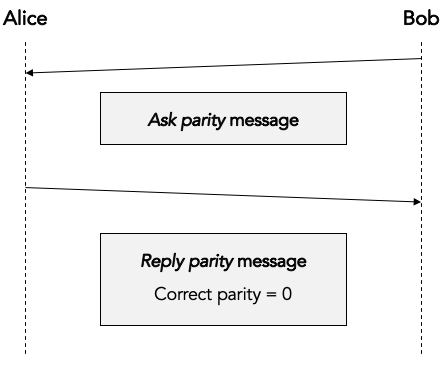
In any real implementation there would be additional fields in the reply message to associate the reply parity message with the corresponding ask parity message, but we gloss over those details here.
Although neither Alice nor Bob ever divulge any actual key bits, the divulgence of the correct parity in the reply parity message does leak a little bit of information to Eve. This is easy to understand if we look at the number of values Eve has to try out in a brute force attack. If Eve knows nothing about N bits, she has to try out 2N values in a brute force attack. But if she knows the parity of those N bits, she only has to try out 2N-1 values.
Inference the error parity from current parity and the correct parity.
At this point Bob knows both the correct parity and the current parity of the block.
Can Bob determine which bits in the block are in error? Well, no, he cannot. Can Bob at least determine whether there are any errors in the block or not? Well, no, he cannot determine even that.
What can Bob determine then? Well, Bob can determine whether there are an even or an odd number of errors in the block (the so-called error parity), by using the following table:
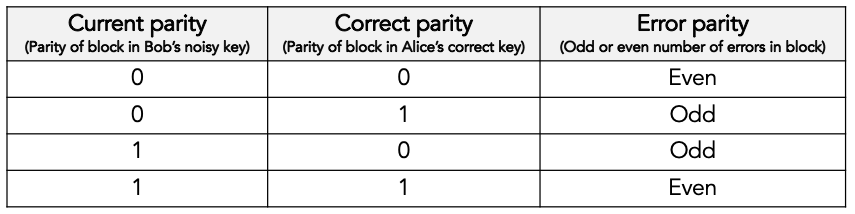
If the error parity is odd, then Bob knows that there is at least bit one error in the block. He doesn’t know exactly how many bit errors there are: it could be 1 or 3 or 5 or 7 etc. And he certainly doesn’t which which key bits are in error.
If the error parity is even, then Bob knows even less. Remember that zero is an even number. So, there could be no (zero) errors, or there could be some (2, 4, 6, etc.) errors.
Correcting a single bit error in top-level blocks with an odd number of bits.
When Bob finds a block with an even number of errors, Bob does nothing with that block (for now).
But when Bob finds a block with an odd number of errors, Bob knows that there is at least one remaining bit error in the block. Bob doesn’t know whether there is 1 or 3 or 5 etc. bit errors, but he does now there is at least one bit error and that the number is odd. For such a block, Bob executes the Binary algorithm. We will describe the Binary algorithm in the next section. For now, suffice it to say that the Binary algorithm finds and corrects exactly one bit error in the block.
Let’s summarize what we have done so far.
In each iteration (except the first) Bob first shuffles the noisy key. Then he takes the shuffled key and breaks it up into blocks. Then he visits every block and determines the error parity for that block. If the error parity is even, he does nothing. If the error parity is odd, then he runs the Binary algorithm to correct exactly one bit errors.
So, at the end of the iteration, Bob ends up with a list of blocks that all have an even error parity.
Some blocks already had an even error parity at the beginning of the iteration and Bob did not touch them.
Some blocks had an odd error parity at the beginning of the iteration and Bob ran the Binary algorithm to correct exactly one bit error. If you start with a block with an odd number of bit errors, and you correct exactly one bit error, then you end up with a block with an even number of bit errors.
Does this mean that we have removed all errors during this iteration? No it does, not. We only know that each block now contains an even number of errors. It could be zero errors. But it could also be 2, 4, 6, etc. errors.
During this iterations there is nothing more Bob can do to find or correct those remaining errors. But that doesn’t mean those remaining error won’t get corrected. Later we will see how a combination of reshuffling in later iterations and the so-called cascading effect will (with high probability) find and correct those remaining errors.
The Binary algorithm.
The Binary algorithm takes as input a block that has an odd number of errors. It finds and corrects exactly one bit error.
Bob is only allowed to run the Binary algorithm on blocks that have an odd number of errors. Bob is not allowed to run the Binary algorithm on a block that has an even number of errors (it is a useful exercise to figure out why not).
Split block.
The first thing Binary does is to split the block into two sub-blocks of equal size. We call these sub-blocks the left sub-block and the right sub-block. And we call the block that was split the parent block. If the parent block has an odd size, then the left sub-block is one bit bigger than the right sub-block.

Given the fact that we know for certain that the parent block has an odd number of errors, there are only two possibilities for the sub-blocks.
Either the left sub-block has an odd number of errors and the right sub-block has an even number of errors, as in the following examples:

Or the left sub-block has an even number of errors and the right sub-block has an odd number of errors, as in the following examples:

It is simply not possible that both sub-blocks have an even number of errors and it is also not possible that both sub-blocks have an odd number of errors.
Determine error parity of sub-blocks.
Bob doesn’t know which it is: Bob doesn’t know whether the left sub-block or the right sub-block has an odd number of errors. All Bob knows at this point is that the parent block has an odd number of errors.
In order to find out, Bon sends an ask parity message to Alice to ask the correct parity for the left sub-block (only the left sub-block, not the right sub-block). When Alice responds with the correct parity for the left sub-block, Bob can compute the error parity (odd or even) for the left sub-block: he just needs to combine the locally computed current parity with the correct parity provided by Alice.
If the error parity of the left sub-block turns out to be odd, then Bob immediately knows that the error parity of the right sub-block must be even.
On the other hand, if the error parity of the left sub-block turns out to be even, then Bob immediately knows that the error parity of the right sub-block must be odd.
Either way, Bob knows the error parity of both the left sub-block and the right sub-block. Bob only asked Alice to give the correct parity for the left sub-block. Bob never asked Alice to provide the correct parity for the right sub-block. Bob can infer the correct parity and hence error parity for the right sub-block (and so can Eve, by the way).
By the way, this inference trick only works if Bob knows for a fact that the error parity of the parent block is odd. That is why Bob is not allowed to run the Binary protocol on a block with even error parity.
Recursion.
Once Bob has determined whether the left sub-block or the right sub-block contains an odd number of errors, Bob can recursively apply the Binary algorithm to that sub-block.
The Binary algorithm will keep recursing into smaller and smaller sub-blocks, until it finally reaches a sub-block that has a size of only a single bit.
If we have a sub-block whose size is one single bit and we also know that that same sub-block has an odd number of errors, then we can conclude that the single bit must be in error. We have found our single error bit that we can correct!
Let’s look at a detailed example to get a better feel for how this works in practice:
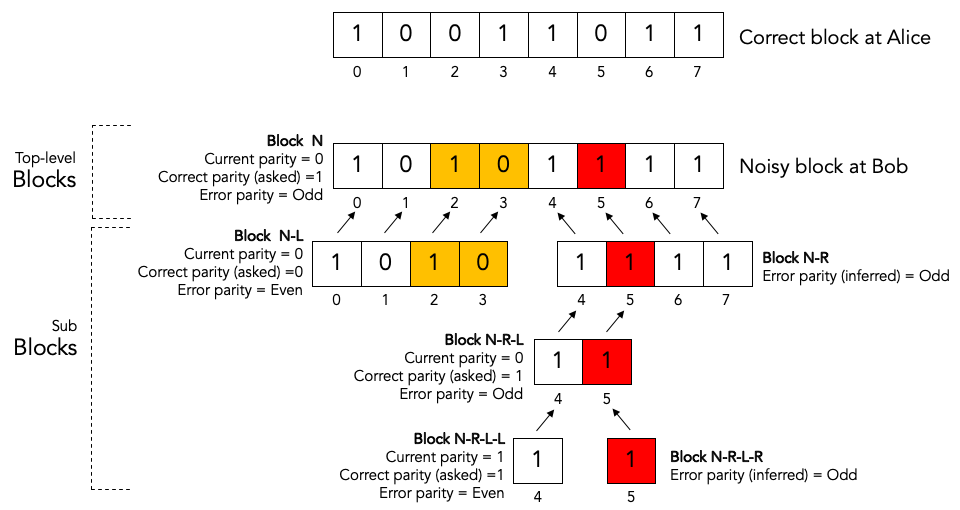
Bob has received a noisy key from Alice, he has shuffled that key, and he has split the shuffled key into top-level blocks. The block labeled “noisy block at Bob” is one of those blocks. Let’s just call it block N.
For the sake of clarity we have show corresponding block in the correct key at Alice as well. This is the block labeled “correct block at Alice”.
As we can see, there are three bit errors in the noisy top-level block, namely the colored blocks at block indexes 2, 3 and 5.
We will now show how the Binary algorithm will detect and correct exactly one of those errors, namely the red one at block index 5.
The other two errors, the orange onces at block index 2 and 3, will neither be detected nor corrected by the Binary algorithm.
Here are the steps:
Bob splits top-level block N into two sub-blocks: the left sub-block N-L, and the right sub-block N-R.
Bob determines the error parity for the blocks N-L and N-R as follows:
2a. Bob computes the current parity over block N-L and finds that it is 0.
2b. Bob asks Alice for the correct parity over block N-L and gets the answer that it is 0.
2c. Since the current parity and the correct parity for block N-L are the same, Bob concludes that the error parity must be even.
2d. Bob infers that block N-R must have odd error parity.
Bob recurses in the to sub-block with odd error parity, which is block N-R.
Bob splits sub-block N-R into two sub-sub-blocks: the left sub-sub-block N-R-L, and the right sub-sub-block N-R-R.
Bob determines the error parity for the blocks N-R-L and N-R-R as follows:
5a. Bob computes the current parity over block N-R-L and finds that it is 0.
5b. Bob asks Alice for the correct parity over block N-R-L and gets the answer that it is 1.
5c. Since the current parity and the correct parity for block N-R-L are the different, Bob concludes that the error parity must be odd.
5d. Bob doesn’t care about block N-R-R because he has already found his block to recurse into.
Bob recurses in the to sub-sub-block with odd error parity, which is block N-R-L.
Bob splits sub-sub-block N-R-L into two sub-sub-sub-blocks: the left sub-sub-sub-block N-R-L-L, and the right sub-sub-sub-block N-R-L-R.
Bob determines the error parity for the blocks N-R-L-L and N-R-L-R as follows:
8a. Bob computes the current parity over block N-R-L-L and finds that it is 1.
8b. Bob asks Alice for the correct parity over block N-R-L-L and gets the answer that it is 1.
8c. Since the current parity and the correct parity for block N-R-L-L are the same, Bob concludes that the error parity must be even.
8d. Bob infers that block N-R-L-R must have odd error parity.
Bob notices that block N-R-L-R has a size of only one bit. Bob has found an error and corrects that error by flipping the bit!
What about the remaining errors after correcting a single bit error?
Now consider what happens after Bob has used the Binary protocol to correct a single bit error in a block.
Before the correction the block had an odd number of errors, which means that after the correction the block will contain an even number of errors. It may be error-free (have 0 remaining errors), or it it may not yet be error-free (have 2, 4, 6, etc. remaining errors).
There is no way for Bob to know whether there are any errors left, and even if he did, Bob could not run the Binary algorithm on the same block again since the Binary algorithm can only be run on blocks with odd error parity. There is nothing left for Bob to do with the block, at least not during this iteration.
So what about the remaining errors in the block (if any)? How will they get corrected? There are two mechanisms:
Reshuffling in later iterations.
The cascading effect.
We will now discuss each of these mechanisms in turn.
The role of shuffling in error correction.
The following diagram show the situation that Bob might find himself in at the end of some iteration, say iteration number N:
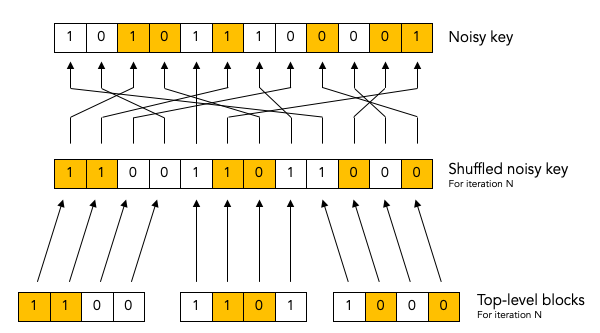
Maybe Bob already corrected a bunch of errors, but there are still six remaining errors left to correct.
Unfortunately, every top-level block contains an even number of remaining errors, so Bob is not able to make any progress during this iteration.
Bob has no choice but to move on to the next iteration N+1. In the next iteration, Bon reshuffles the keys (using a different shuffling order). Then he breaks up the reshuffled key into top-level blocks again, but using bigger blocks this time.
We might up with something like this at the beginning of iteration N+1:
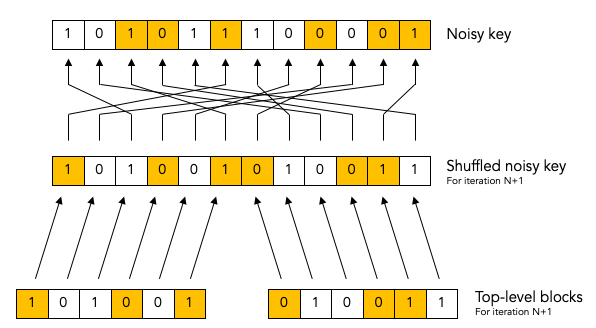
It is possible that at the beginning of iteration N+1 Bob ends up with some blocks that have an odd number of errors. Indeed, in this example Bob is quite lucky both remaining blocks have an odd number of errors (3 errors in each block).
Now Bob can make progress again: he can run the Binary algorithm on each block and remove exactly one error in each block. At the end of iteration N+1 there will be 4 errors remaining (2 in each block).
The Cascade effect.
Let’s keep going with same example a little bit more.
If you go through the steps of the Binary protocol, you will see that Bob will end up correcting the two bits that are marked in red during iteration N+1:
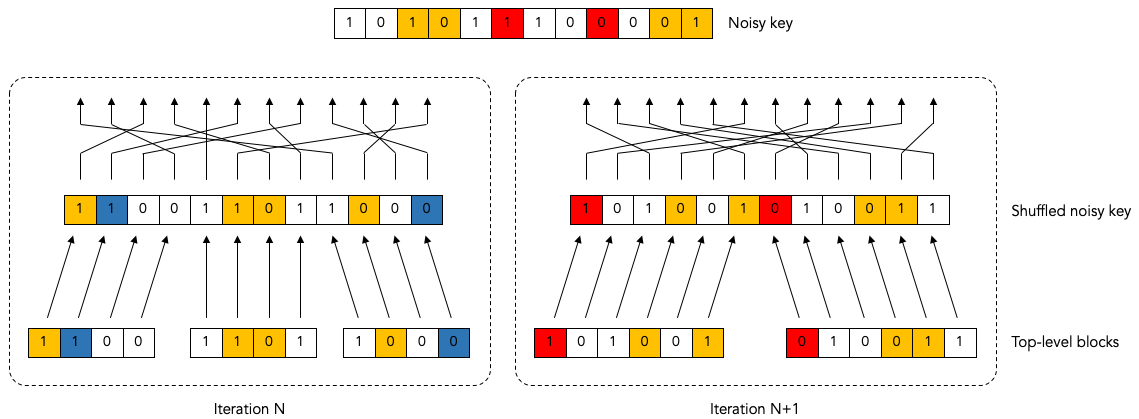
If you follow the arrows from the red corrected bit in the shuffled blocks back to the top you can see which bits in the underlying unshuffled noisy key will end up being corrected (these are also marked in red).
But wait! If are going to be flipping bits (correcting errors) on de underlying unshuffled noisy key, then this is going to have a ripple effect on the shuffled blocks from earlier iterations.
In this particular example, we can see that flipping the red bits in iteration N+1 will cause the blue bits in iteration N to be flipped as a side-effect.
After all the red and blue bit flipping is done, we end up with the following situation:
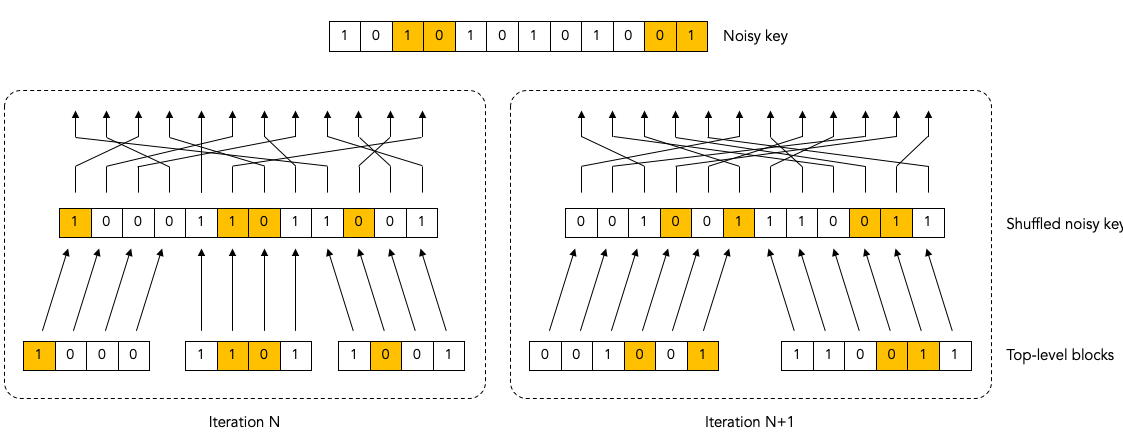
As we discussed before, we have corrected two bit errors in iteration N+1, and now there are 4 bit errors remaining.
And, as expected, we are now stuck as far as iteration N+1 is concerned. We can make no further progress in iteration N+1 because each block has an even number of errors.
But look! Because of the ripple effect on the previous iteration N, we now have two blocks in iteration N that now have an odd number of errors! Bob can go back to those iteration N blocks and re-apply the Binary protocol to correct one more error in them.
This ripple effect is what is called the cascade effect that gives the Cascade protocol its name.
The cascade effect is very profound and much stronger than it seems from our simple example.
Firstly, fixing an error in iteration N does not only affect iteration N, but also iterations N-1, N-2, …, 1.
Secondly, consider what happens when the cascade effect causes us to go back and revisit a block in an earlier iteration and fix another error there. Fixing that error in the earlier block with cause yet another cascade effect in other blocks. Thus, when we correct a single error, the cascade effect can cause a veritable avalanche of other cascaded error corrections.
Parallelization and bulking.
Every time Bob asks Alice to provide the correct parity for a block he sends an ask parity message and then waits for the reply parity response message.
If Alice is in Amsterdam and Bob is in Boston they are 5,500 km apart. The round-trip delay of the ask parity and reply parity messages will be 110 milliseconds (the speed of light in fiber is 200,000 km/sec) plus whatever time Alice needs to process the message.
During the reconciliation of a single large key Bob can ask Alice for many parities (hundreds of ask parities for a 10,000 bit key, for example).
If Bob processes all blocks serially, i.e. if Bob doesn’t start working on the next block until he has completely finished the Binary algorithm for the previous block, then the total delay will be very long. If we assume 200 ask parity messages, it will add up to at least a whopping 22 seconds. That is clearly too slow.
5,500 km was a bit extreme, just to make a point. But even for more realistic distances for quantum key distribution, say 50 km, the round-trip time delay is significant.
Luckily Bob does not have to process all blocks sequentially; he can do some parallel processing of blocks.
The lowest hanging fruit to to parallelize the processing of the top-level blocks. At the beginning of each iteration, Bob shuffles the key and splits it up into top-level blocks. Bob can then send a single “bulked” ask parities (plural) message asking Alice for all the parities of all the top-level blocks in that iteration. Alice sends a single reply parities (plural) message with all correct parities. Then Bob can start processing all the top-level blocks.
But to get the full effect of parallelization Bob must do more. When Bob, in the process of running the Binary algorithm, gets to the point that he needs to ask Alice for the parity of a sub-block, Bob should not block and do nothing, waiting for the answer from Alice. Instead, Bob should send the ask parity message and then go work on some other block that has an odd number of errors “in parallel” while waiting for the answer to the first message. Working on multiple sub-blocks “in parallel” greatly reduces the total latency for an iteration.
If, in addition to reducing the latency, Bob also wants to reduce the number of ask parity messages, Bob can do “bulking” of messages. When Bob needs to ask Alice for the parity for some block B1, Bob can already start working on some other block B2. But instead of immediately sending the ask parity message for block B1, Bob can hold off for some time in anticipation of probably having to ask to parity for some other parities as well.
Note that the bulking of messages reduces the number of messages bit it does very little to reduce the volume (i.e. total number of bytes) of messages.
In the extreme case, Bob can hold off sending any ask parities message until he can absolutely positively not make any more progress before he gets an answer. But that would increase the latency again because it would force Bob to sit idle not doing anything.
The sweet spot is probably to hold off sending ask parity messages for only a fixed delay (similar to what the Nagle algorithm does in TCP/IP).
Information Leakage and Privacy Amplification.
The goal of QKD is for Alice and Bob to agree on a shared secret key in such a manner that eavesdropper Eve cannot discover what the secret key is, even if Eve can monitor all communications between Alice and Bob, including the Cascade messages (which are assumed to be authenticated but public).
Every time the Cascade protocol exposes a parity bit in a reply parity message, one bit of information about the key is leaked to Eve. Intuitively it is clear that if Eve knows one parity bit for the key, she would only have to consider ½ of the possible keys in a brute force attack; the other ½ would not have the correct parity. And if Eve knows two parity bits for the key, should would only have to consider ¼ of the possible keys; the other ¾ would not have the correct parity.
Thus, we can see that for every exposed parity bit, the effective usable key length is reduced by one bit. The privacy amplification step, which takes part after the Cascade information reconciliation step in classical post-processing, takes care of reducing the key length and erasing any information that was exposed by the parity bits in the Cascade protocol.
Efficiency.
Cascade is not the only QKD information reconciliation protocol. For example, Low Density Parity Check (LDPC) codes are also quite popular, perhaps even more popular these days.
A natural question to ask, then, is: which information reconciliation protocol is the best?
There are different ways to evaluate the goodness of an information reconciliation protocol. One criterium that is often discussed is efficiency η. This is a measure of how much information is leaked. The less information is leaked, the less key material has to be sacrificed during privacy amplification and the better the information reconciliation protocol.
In order to compute the efficiency η we consider a hypothetical perfect information reconciliation protocol, which leaks the least possible amount of information to Eve.
In the field of information theory, it has been proven that there is a lower bound on the amount of information that must be leaked by any information reconciliation protocol, namely:
Lower bound on number of leaked bits = K H(ε)
where
K is the key length,
ε is the Quantum Bit Error Rate (QBER) in the key before information reconciliation,
H(ε) = -ε log2(ε) - (1-ε) log2(1-ε) is the binary entropy function.
The efficiency η of the Cascade protocol (or of any information reconciliation protocol, for that matter) is then computed as follows:
η = N / K H(ε)
where N is the number of leaked parity bits.
The efficiency η is a number greater than 1. For example, efficiency 1.25 means that the Cascade protocol is leaking 25% more bits than the theoretical minimum.
When we implemented the Cascade protocol in Python and C++, we ran many experiments with different Cascade algorithm variations, key lengths, and error rates. We computed the efficiency of the Cascade protocol for all these scenarios and compared the results with those reported in literature.
For example, the following graphs show the efficiency of two variations of the Cascade protocol as a function to the noise (the bit error rate). The first graph is computed by our C++ implementation and the second graph is reported in literature.
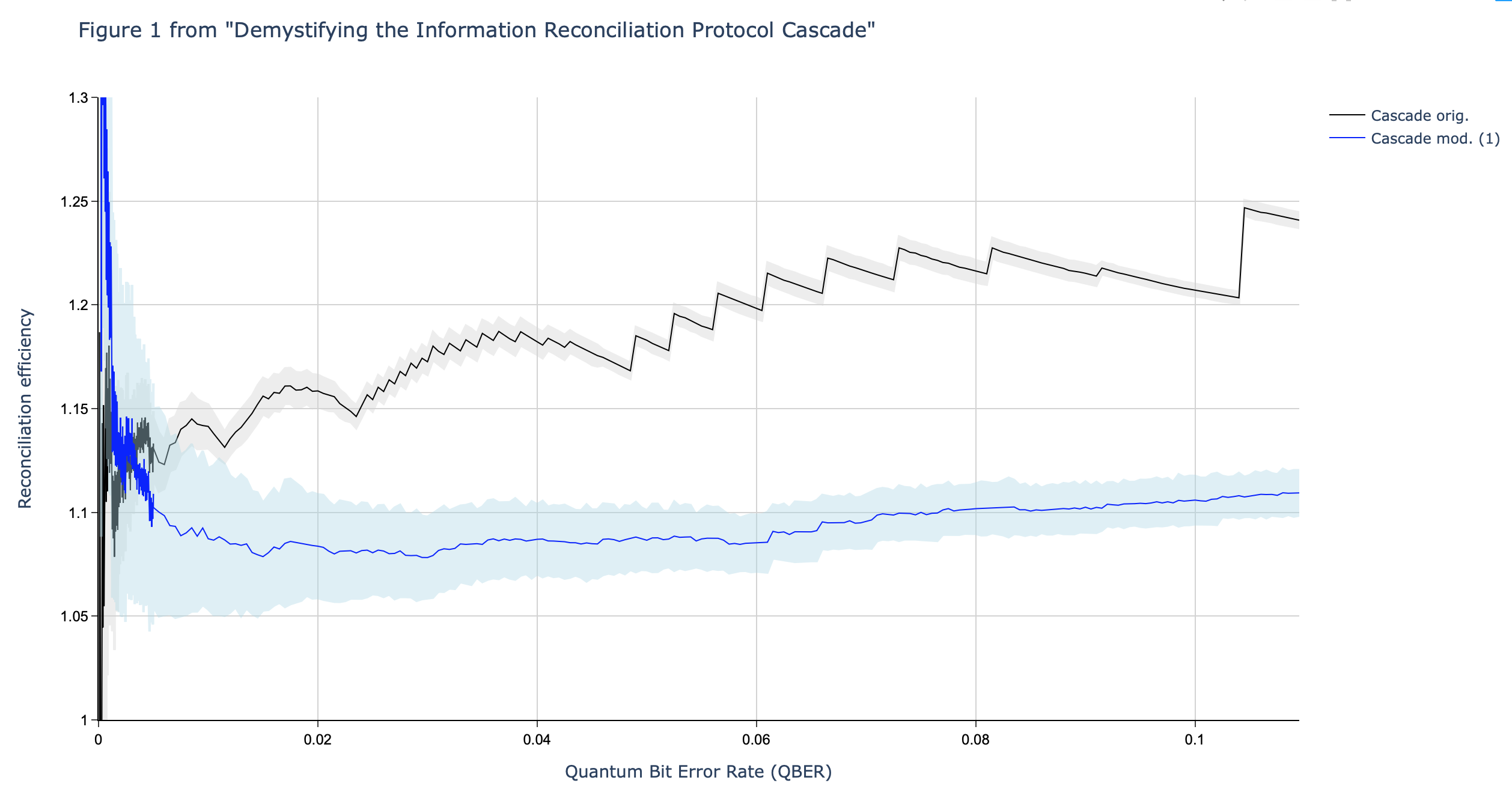
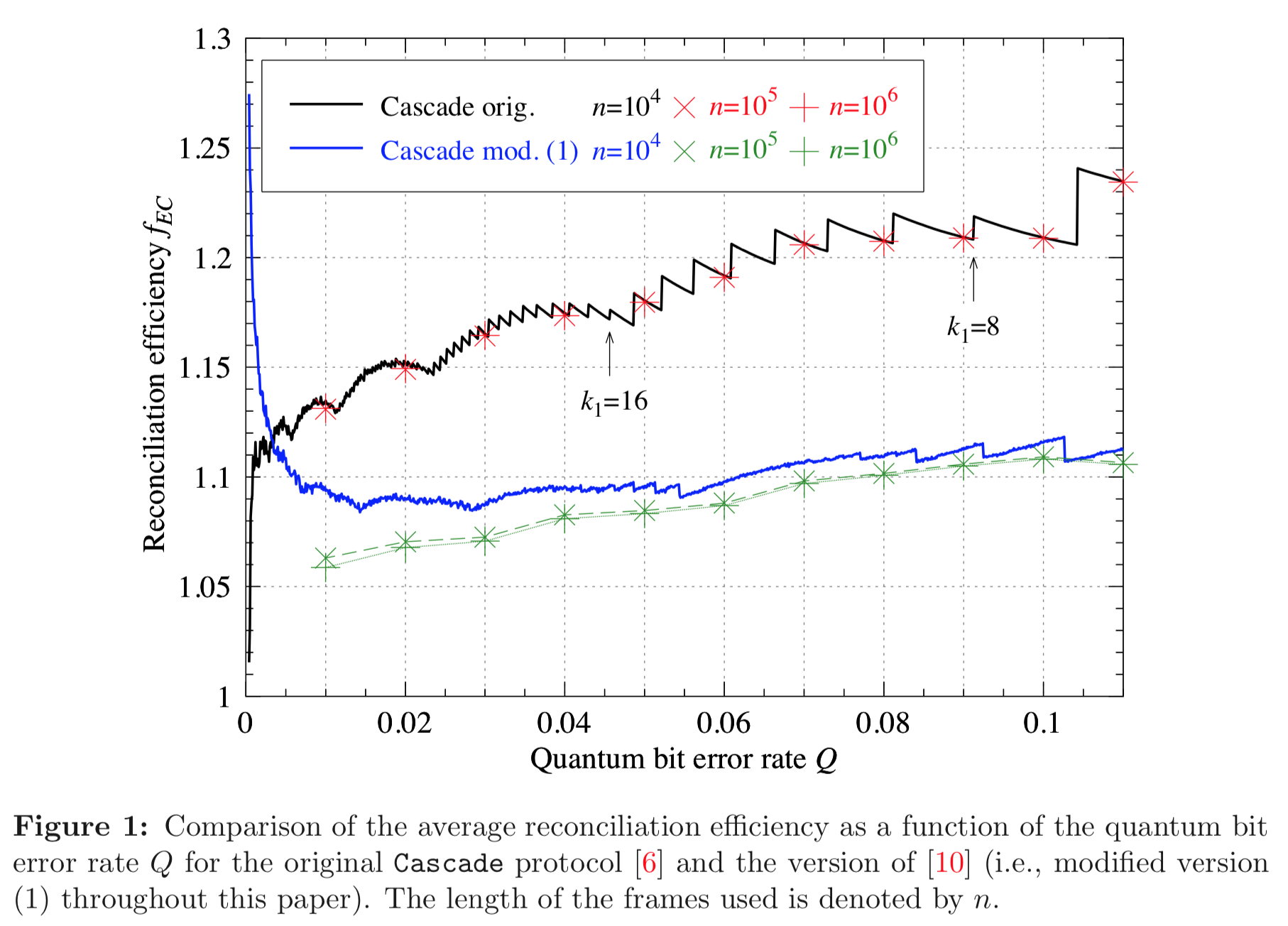
For the standard Cascade protocol we get an efficiency of about 1.2, and for the modified Cascade protocol we get an efficiency of about 1.1. Both are considered to be very good. In other words, relatively little information (about 20% and 10% respectively) is leaked.
Channel uses.
Another criterium for evaluating the goodness of an information reconciliation protocol is the number of channel uses. This is the number of classical control plane messages that Alice sends to Bob or vice versa. In the case of Cascade, we could how many ask parity messages Bob sends to Alice and how many reply parity messages Alice sends back to Bob.
What matters is that each ask-reply message pair incurs a round-trip delay. If we consider, for example, a QKD link of 200 km and we take the speed of light in fiber which is roughly 200,000 km/sec, then we see that each round-trip takes at least 1 ms. We have to add to this the processing times at Alice and Bob for each block.
For example, the following graphs show the number of channel uses in Cascade protocol as a function of frame length (key size) for three different error rates. Again, the first graph is computed by our C++ implementation and the second graph is reported in literature.
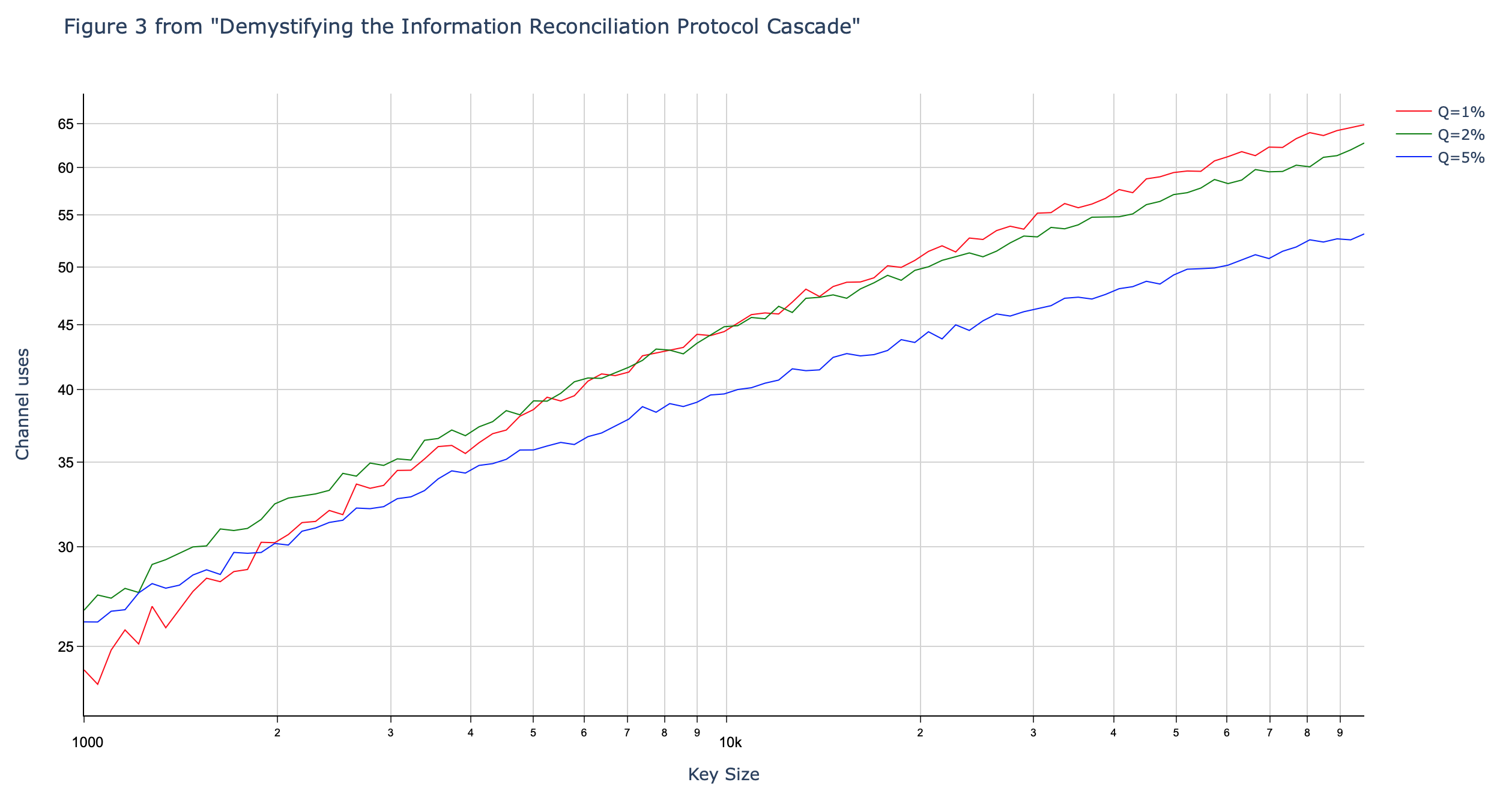
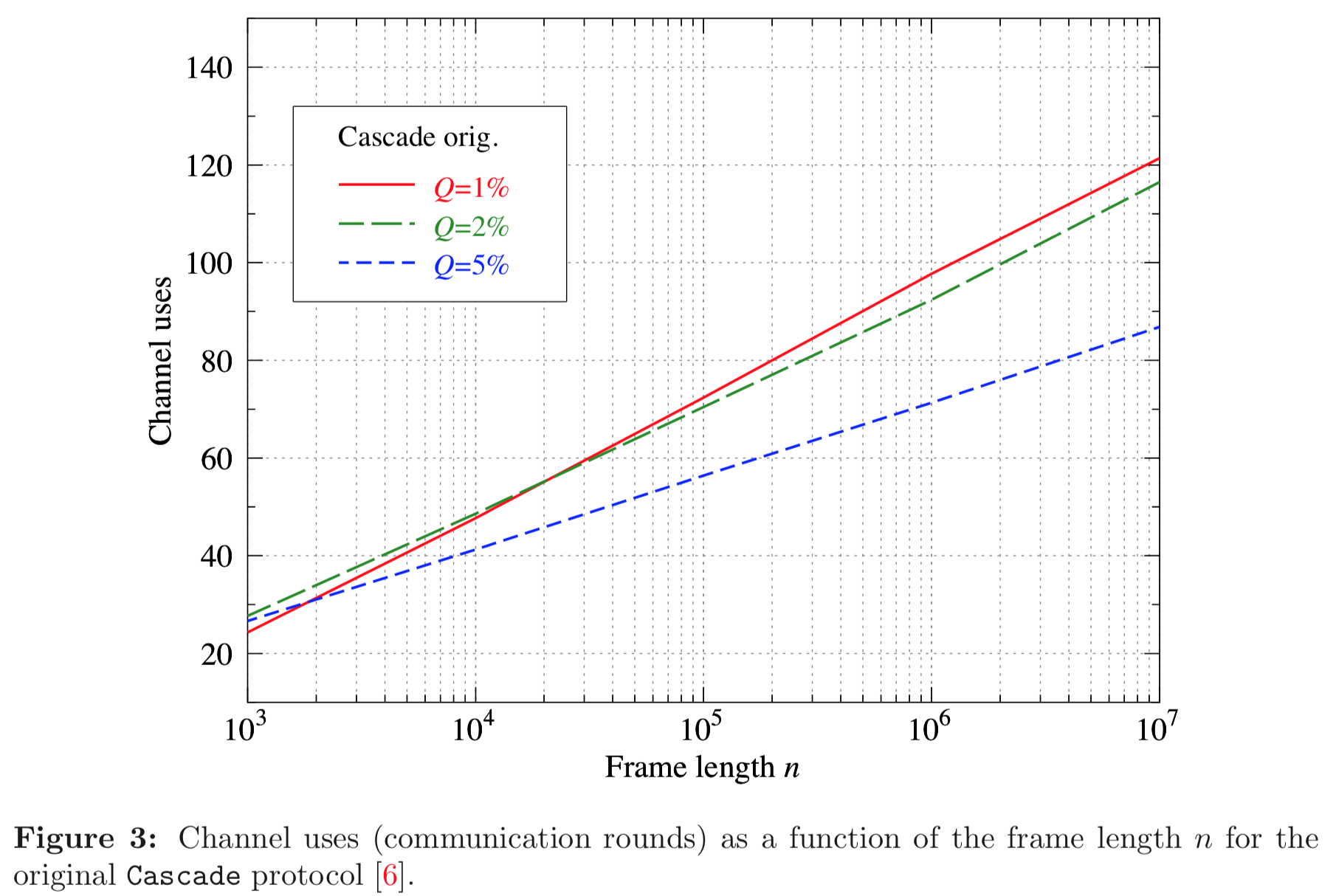
We already noted that the Cascade protocol is very interactive, requiring many (between 20 and 120) back-and-forth message exchanges between Alice and Bob. Although our C++ implementation takes great care to do as much parallelization as possible (already start on the next block before the reply for the previous block has been received), this interactive nature can still make the Cascade protocol slow. Other information reconciliation protocols, such as Low Density Parity Check (LDPC) codes require only a single message exchange.
Variations on the Cascade Protocol.
TODO: Discuss variations on Cascade protocol.
TODO: Different number of iterations.
TODO: Different functions for calculation block size.
TODO: BICONF.
TODO: Sub-block re-use.
TODO: Block parity inference (BPI).
TODO: Deterministic vs random shuffle.
TODO: Discarding of corrected bits.